
lvs (linux virtual server) 是一个负载均衡器,也可以说是一个tcp/ip协议的反向代理,可以将用户的tcp请求转发到它所代理的真实的后端服务起上,起到服务响应扩容或提高服务并发能力的作用
lvs只是一个内核模块ip_vs,没有具体的服务, lvs 提供一个接口,通过安装ipvsadm 这个工具来实现对lvs管理
lvs 工作在tcp/ip协议栈中,也就是说它工作在内核空间中,计算机工作进程空间,分为内核空间和用户空间,分别在于资源利用的优先级、内存的隔离性、响应速度的不同,内核空间主要用来运行系统内核,所以对资源利用
的优先级会高,响应速度快,用户空间就是我们一般应用程序所在的内存空间
lvs工作在input及postrouting链上(防火墙的两条链,所以开启lvs不能开起防火墙), 在这两条链上通过修改请求的tcp/ip头部信息达到转发的作用
lvs 具体是如何转发请求到真实服务器集群上?有4中方式:
nat 模式:修改请求的ip及端口到后端真实服务器,lvs与服务器集群在同一个网段内
dr 模式:修改请求的mac地址到后段真实服务器,lvs与服务器集群在同一个网段内
ip turnel:在请求头上增加ip头,跨网转发,lvs与服务器集群在不同的网段
fullnat:在nat模式下修改用来夸不同vlan,既增加ip turnel头又修改内网ip头
由 于IPv4中IP地址空间的日益紧张和安全方面的原因,很多网络使用保留IP地址(10.0.0.0/255.0.0.0、 172.16.0.0/255.128.0.0和192.168.0.0/255.255.0.0)[64, 65, 66]。这些地址不在Internet上使用,而是专门为内部网络预留的。当内部网络中的主机要访问Internet或被Internet访问时,就需要 采用网络地址转换(Network Address Translation, 以下简称NAT),将内部地址转化为Internets上可用的外部地址。NAT的工作原理是报文头(目标地址、源地址和端口等)被正确改写后,客户相信 它们连接一个IP地址,而不同IP地址的服务器组也认为它们是与客户直接相连的。由此,可以用NAT方法将不同IP地址的并行网络服务变成在一个IP地址 上的一个虚拟服务。
VS/NAT的体系结构如图2所示。在一组服务器前有一个调度器,它们是通过Switch/HUB相连接的。这些服务器 提供相同的网络服务、相同的内容,即不管请求被发送到哪一台服务器,执行结果是一样的。服务的内容可以复制到每台服务器的本地硬盘上,可以通过网络文件系 统(如NFS)共享,也可以通过一个分布式文件系统来提供。
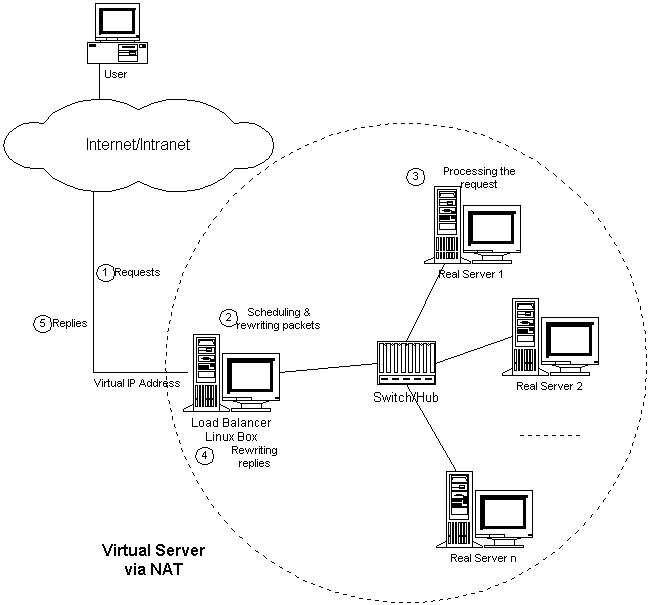

图2:VS/NAT的体系结构
客 户通过Virtual IP Address(虚拟服务的IP地址)访问网络服务时,请求报文到达调度器,调度器根据连接调度算法从一组真实服务器中选出一台服务器,将报文的目标地址 Virtual IP Address改写成选定服务器的地址,报文的目标端口改写成选定服务器的相应端口,最后将修改后的报文发送给选出的服务器。同时,调度器在连接Hash 表中记录这个连接,当这个连接的下一个报文到达时,从连接Hash表中可以得到原选定服务器的地址和端口,进行同样的改写操作,并将报文传给原选定的服务 器。当来自真实服务器的响应报文经过调度器时,调度器将报文的源地址和源端口改为Virtual IP Address和相应的端口,再把报文发给用户。我们在连接上引入一个状态机,不同的报文会使得连接处于不同的状态,不同的状态有不同的超时值。在TCP 连接中,根据标准的TCP有限状态机进行状态迁移,这里我们不一一叙述,请参见W. Richard Stevens的《TCP/IP Illustrated Volume I》;在UDP中,我们只设置一个UDP状态。不同状态的超时值是可以设置的,在缺省情况下,SYN状态的超时为1分钟,ESTABLISHED状态的超 时为15分钟,FIN状态的超时为1分钟;UDP状态的超时为5分钟。当连接终止或超时,调度器将这个连接从连接Hash表中删除。
这样,客户所看到的只是在Virtual IP Address上提供的服务,而服务器集群的结构对用户是透明的。对改写后的报文,应用增量调整Checksum的算法调整TCP Checksum的值,避免了扫描整个报文来计算Checksum的开销。
在 一些网络服务中,它们将IP地址或者端口号在报文的数据中传送,若我们只对报文头的IP地址和端口号作转换,这样就会出现不一致性,服务会中断。所以,针 对这些服务,需要编写相应的应用模块来转换报文数据中的IP地址或者端口号。我们所知道有这个问题的网络服务有FTP、IRC、H.323、 CUSeeMe、Real Audio、Real Video、Vxtreme / Vosiac、VDOLive、VIVOActive、True Speech、RSTP、PPTP、StreamWorks、NTT AudioLink、NTT SoftwareVision、Yamaha MIDPlug、iChat Pager、Quake和Diablo。
下面,举个例子来进一步说明VS/NAT,如图3所示:
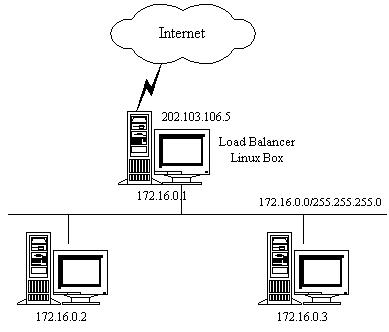
图3:VS/NAT的例子
VS/NAT 的配置如下表所示,所有到IP地址为202.103.106.5和端口为80的流量都被负载均衡地调度的真实服务器172.16.0.2:80和 172.16.0.3:8000上。目标地址为202.103.106.5:21的报文被转移到172.16.0.3:21上。而到其他端口的报文将被拒 绝。
| Protocol | Virtual IP Address | Port | Real IP Address | Port | Weight |
| TCP | 202.103.106.5 | 80 | 172.16.0.2 | 80 | 1 |
| 172.16.0.3 | 8000 | 2 | |||
| TCP | 202.103.106.5 | 21 | 172.16.0.3 | 21 | 1 |
从以下的例子中,我们可以更详细地了解报文改写的流程。
访问Web服务的报文可能有以下的源地址和目标地址:
| SOURCE | 202.100.1.2:3456 | DEST | 202.103.106.5:80 |
调度器从调度列表中选出一台服务器,例如是172.16.0.3:8000。该报文会被改写为如下地址,并将它发送给选出的服务器。
| SOURCE | 202.100.1.2:3456 | DEST | 172.16.0.3:8000 |
从服务器返回到调度器的响应报文如下:
| SOURCE | 172.16.0.3:8000 | DEST | 202.100.1.2:3456 |
响应报文的源地址会被改写为虚拟服务的地址,再将报文发送给客户:
| SOURCE | 202.103.106.5:80 | DEST | 202.100.1.2:3456 |
这样,客户认为是从202.103.106.5:80服务得到正确的响应,而不会知道该请求是服务器172.16.0.2还是服务器172.16.0.3处理的。
在VS/NAT 的集群系统中,请求和响应的数据报文都需要通过负载调度器,当真实服务器的数目在10台和20台之间时,负载调度器将成为整个集群系统的新瓶颈。大多数 Internet服务都有这样的特点:请求报文较短而响应报文往往包含大量的数据。如果能将请求和响应分开处理,即在负载调度器中只负责调度请求而响应直 接返回给客户,将极大地提高整个集群系统的吞吐量。
IP隧道(IP tunneling)是将一个IP报文封装在另一个IP报文的技术,这可以使得目标为一个IP地址的数据报文能被封装和转发到另一个IP地址。IP隧道技 术亦称为IP封装技术(IP encapsulation)。IP隧道主要用于移动主机和虚拟私有网络(Virtual Private Network),在其中隧道都是静态建立的,隧道一端有一个IP地址,另一端也有唯一的IP地址。
我们利用IP隧道技术将请求报文封装转 发给后端服务器,响应报文能从后端服务器直接返回给客户。但在这里,后端服务器有一组而非一个,所以我们不可能静态地建立一一对应的隧道,而是动态地选择 一台服务器,将请求报文封装和转发给选出的服务器。这样,我们可以利用IP隧道的原理将一组服务器上的网络服务组成在一个IP地址上的虚拟网络服务。 VS/TUN的体系结构如图4所示,各个服务器将VIP地址配置在自己的IP隧道设备上。
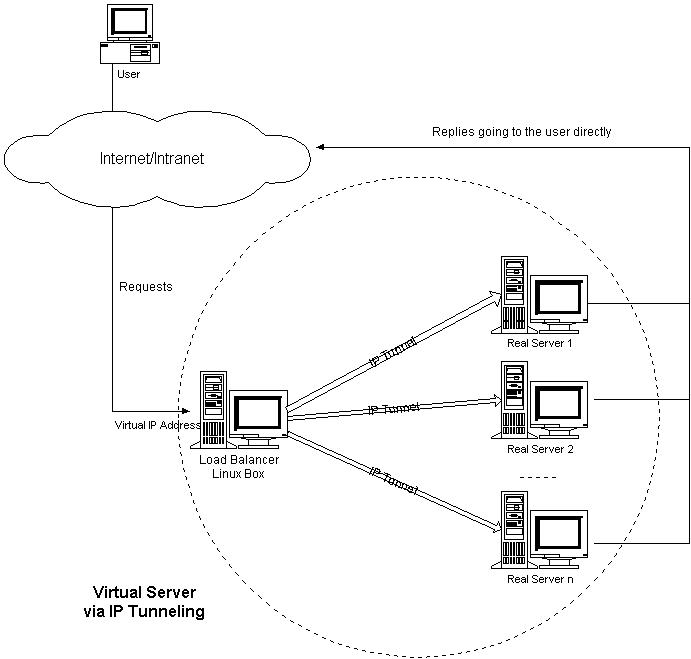
图4:VS/TUN的体系结构
VS/TUN 的工作流程如图5所示:它的连接调度和管理与VS/NAT中的一样,只是它的报文转发方法不同。调度器根据各个服务器的负载情况,动态地选择一台服务器, 将请求报文封装在另一个IP报文中,再将封装后的IP报文转发给选出的服务器;服务器收到报文后,先将报文解封获得原来目标地址为VIP的报文,服务器发 现VIP地址被配置在本地的IP隧道设备上,所以就处理这个请求,然后根据路由表将响应报文直接返回给客户。
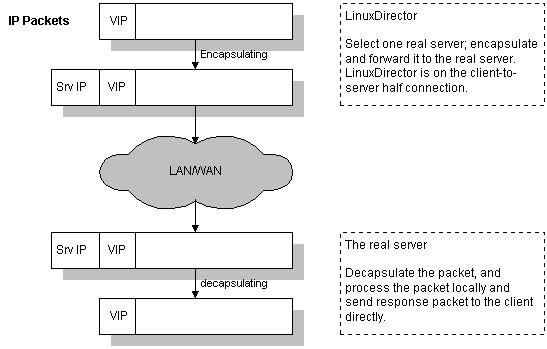
图5:VS/TUN的工作流程
在这里需要指出,根据缺省的TCP/IP协议栈处理,请求报文的目标地址为VIP,响应报文的源地址肯定也为VIP,所以响应报文不需要作任何修改,可以直接返回给客户,客户认为得到正常的服务,而不会知道究竟是哪一台服务器处理的。
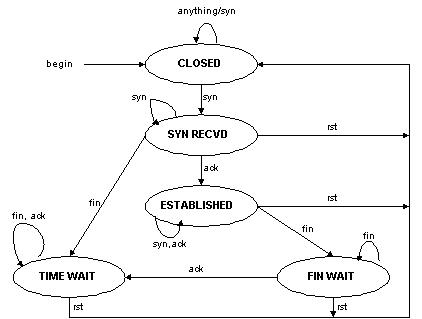
图6:半连接的TCP有限状态机
跟VS/TUN 方法相同,VS/DR利用大多数Internet服务的非对称特点,负载调度器中只负责调度请求,而服务器直接将响应返回给客户,可以极大地提高整个集群 系统的吞吐量。该方法与IBM的NetDispatcher产品中使用的方法类似(其中服务器上的IP地址配置方法是相似的),但IBM的 NetDispatcher是非常昂贵的商品化产品,我们也不知道它内部所使用的机制,其中有些是IBM的专利。
VS/DR的体系结构如图 7所示:调度器和服务器组都必须在物理上有一个网卡通过不分断的局域网相连,如通过高速的交换机或者HUB相连。VIP地址为调度器和服务器组共享,调度 器配置的VIP地址是对外可见的,用于接收虚拟服务的请求报文;所有的服务器把VIP地址配置在各自的Non-ARP网络设备上,它对外面是不可见的,只 是用于处理目标地址为VIP的网络请求。
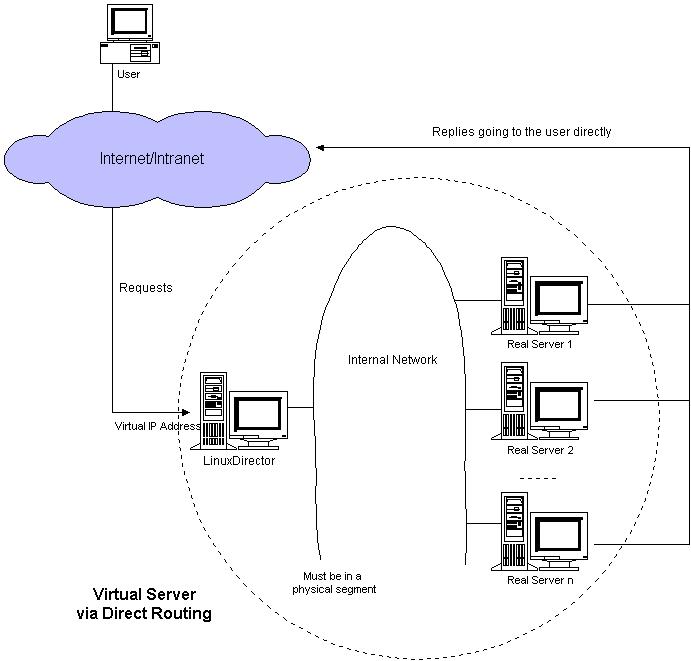
图7:VS/DR的体系结构
VS/DR 的工作流程如图8所示:它的连接调度和管理与VS/NAT和VS/TUN中的一样,它的报文转发方法又有不同,将报文直接路由给目标服务器。在VS/DR 中,调度器根据各个服务器的负载情况,动态地选择一台服务器,不修改也不封装IP报文,而是将数据帧的MAC地址改为选出服务器的MAC地址,再将修改后 的数据帧在与服务器组的局域网上发送。因为数据帧的MAC地址是选出的服务器,所以服务器肯定可以收到这个数据帧,从中可以获得该IP报文。当服务器发现 报文的目标地址VIP是在本地的网络设备上,服务器处理这个报文,然后根据路由表将响应报文直接返回给客户。
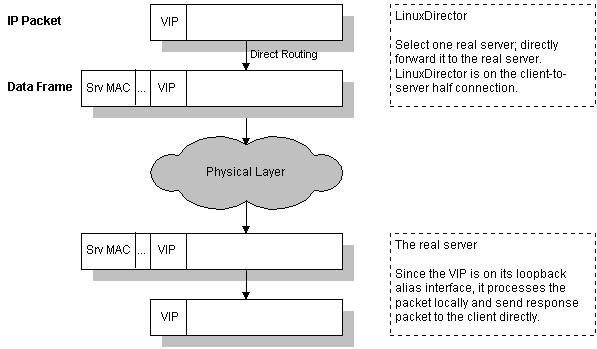
图8:VS/DR的工作流程
在VS/DR中,根据缺省的TCP/IP协议栈处理,请求报文的目标地址为VIP,响应报文的源地址肯定也为VIP,所以响应报文不需要作任何修改,可以直接返回给客户,客户认为得到正常的服务,而不会知道是哪一台服务器处理的。
VS/DR负载调度器跟VS/TUN一样只处于从客户到服务器的半连接中,按照半连接的TCP有限状态机进行状态迁移。
三种IP负载均衡技术的优缺点归纳在下表中:
| _ | VS/NAT | VS/TUN | VS/DR |
| Server | any | Tunneling | Non-arp device |
| server network | private | LAN/WAN | LAN |
| server number | low (10~20) | High (100) | High (100) |
| server gateway | load balancer | own router | Own router |
注: 以上三种方法所能支持最大服务器数目的估计是假设调度器使用100M网卡,调度器的硬件配置与后端服务器的硬件配置相同,而且是对一般Web服务。使用更 高的硬件配置(如千兆网卡和更快的处理器)作为调度器,调度器所能调度的服务器数量会相应增加。当应用不同时,服务器的数目也会相应地改变。所以,以上数 据估计主要是为三种方法的伸缩性进行量化比较。
6.1. Virtual Server via NAT
VS/NAT 的优点是服务器可以运行任何支持TCP/IP的操作系统,它只需要一个IP地址配置在调度器上,服务器组可以用私有的IP地址。缺点是它的伸缩能力有限, 当服务器结点数目升到20时,调度器本身有可能成为系统的新瓶颈,因为在VS/NAT中请求和响应报文都需要通过负载调度器。 我们在Pentium 166 处理器的主机上测得重写报文的平均延时为60us,性能更高的处理器上延时会短一些。假设TCP报文的平均长度为536 Bytes,则调度器的最大吞吐量为8.93 MBytes/s. 我们再假设每台服务器的吞吐量为800KBytes/s,这样一个调度器可以带动10台服务器。(注:这是很早以前测得的数据)
基于 VS/NAT的的集群系统可以适合许多服务器的性能要求。如果负载调度器成为系统新的瓶颈,可以有三种方法解决这个问题:混合方法、VS/TUN和 VS/DR。在DNS混合集群系统中,有若干个VS/NAT负载调度器,每个负载调度器带自己的服务器集群,同时这些负载调度器又通过RR-DNS组成简 单的域名。但VS/TUN和VS/DR是提高系统吞吐量的更好方法。
对于那些将IP地址或者端口号在报文数据中传送的网络服务,需要编写相应的应用模块来转换报文数据中的IP地址或者端口号。这会带来实现的工作量,同时应用模块检查报文的开销会降低系统的吞吐率。
6.2. Virtual Server via IP Tunneling
在VS/TUN 的集群系统中,负载调度器只将请求调度到不同的后端服务器,后端服务器将应答的数据直接返回给用户。这样,负载调度器就可以处理大量的请求,它甚至可以调 度百台以上的服务器(同等规模的服务器),而它不会成为系统的瓶颈。即使负载调度器只有100Mbps的全双工网卡,整个系统的最大吞吐量可超过 1Gbps。所以,VS/TUN可以极大地增加负载调度器调度的服务器数量。VS/TUN调度器可以调度上百台服务器,而它本身不会成为系统的瓶颈,可以 用来构建高性能的超级服务器。
VS/TUN技术对服务器有要求,即所有的服务器必须支持“IP Tunneling”或者“IP Encapsulation”协议。目前,VS/TUN的后端服务器主要运行Linux操作系统,我们没对其他操作系统进行测试。因为“IP Tunneling”正成为各个操作系统的标准协议,所以VS/TUN应该会适用运行其他操作系统的后端服务器。
6.3. Virtual Server via Direct Routing
跟VS/TUN方法一样,VS/DR调度器只处理客户到服务器端的连接,响应数据可以直接从独立的网络路由返回给客户。这可以极大地提高LVS集群系统的伸缩性。
跟VS/TUN相比,这种方法没有IP隧道的开销,但是要求负载调度器与实际服务器都有一块网卡连在同一物理网段上,服务器网络设备(或者设备别名)不作ARP响应,或者能将报文重定向(Redirect)到本地的Socket端口上。
本文主要讲述了LVS集群中的三种IP负载均衡技术。在分析网络地址转换方法(VS/NAT)的缺点和网络服务的非对称性的基础上,我们给出了通过IP隧道实现虚拟服务器的方法VS/TUN,和通过直接路由实现虚拟服务器的方法VS/DR,极大地提高了系统的伸缩性。
-
LVS服务基本操作
Ipvsadm:管理集群服务
Ipvs: 工作在内核上,监控在input 链上
Ipvsadm 写规则送到ipvs 而ipvs且套在input上,然后转发到postrouting,
根据ip及端口来确定是否定义了负载均衡服务,定义的服务转发,未定义的不转发本地处理
VIP: virtual ip
RIP:real server ip
DIP:directory ip 与内外通信
CIP:client ip

Lvs 类型:
NAT:地址转换,遵循的法则
1、DR与RS要在同一网段,且一般为私有地址
2、RS的网关必须要指在DIP
3、DR将处理所有的通信,包括进来和出去的
4、DR支持端口映射
5、RS可以使用任意操作系统
6、单独的DR可能成为瓶颈
7、DR需要由两块网卡
8、注意网卡的转发功能
DR:直接路由,遵循的法则
- DR与RS在同一个物理网络中,要根据mac地址转发
- 可以不用是私有地址
- DR仅处理入站请求,响应报文由RS直接响应
- RS的默认网关不能使用DR而是使用该网段的网关
- DR无法实现端口映射,因为DR没有修改ip首部
- 大多数操作系统都可用,要求系统必须能够隐藏VIP
- 能够负责更多的RS
TUN:隧道
- 集群节点可以跨越internet
- RIP必须是公网地址
- DR仅处理入沾请求
- 响应报文由RS完成
- 支持隧道的OS才能用于RS
- 不支持端口映射
调度算法:schedule method
静态调度:不考虑服务器的繁忙程度
rr:轮询
wrr:加权轮询
sh:source hash, 源地址hash,主要是为了实现session affinity 会话绑定
http协议是无状态的,每次请求响应完成后就断开连接,这样在同请求一页面的多个对象时无法管理个对象的关系,被叫做无状态
cookie 服务器用来追踪客户端的小甜点,当客户端第一次访问服务器,服务器会返回以标志信息,保存在客户端的浏览器中,客户端每次请求都会附加cookie认证,以便服务端认证,早期的cookie将标识信息及浏览信息都保存下来,访问网站的时候将所有的信息发给服务端验证,这样其实很危险别人就会获取你的隐私信息,之后发展为轻cookie,只保留完整的标识信息而浏览信息保留在服务器端的缓存内
session:保存在服务器端,保存客户端url、浏览信息
session share
dh:destination hash, 不同客户端同样的请求发送给同一个server,主要用于后端是缓存的应用
动态调度:
Lc:最少链接 ACTIVE*256+INACTIVE 取小的
Wlc:加权最少链接 (ACTIVE*256+INACTIVE)/权重 取小的
Sed:最短期望延迟 (active*256+1)/权重 取小的
Nq:neverqueue 不考虑非活动链接状况
Lblc:基于本地的最少链接,尽可能的选最少的链接,算法与dh相通可能破坏命中率,尽可能的保证同一个请求发送给同一个RS,动态的考虑cache的连接数
Lblcr:基于本地的带复制功能的最少链接
Lvs 默认使用wlc算法
Ipvs是执行框架,ipvsadm能够在框架上操作的软件
查看内核是否已经编译安装了ipvs模块
grep -i ‘vs’ /boot/config-2.6.32-431.el6.x86_64
安装ipvsadm
Yum install –y ipvsadm
Ipvsadm
管理集群服务
1、添加-A -t|u|f service-address [-s scheduler] (指定lvs的调度算法)
-t:tcp 协议的集群
-u:udp 协议集群
Server-address: IP:port
-f:FWM 防火墙标记
Server-address: mark number
2、-E 修改
3、-D 删除
-t|u|f service-address
#ipvsadm –A –t 172.16.100.1:80 –s rr
管理集群服务中RS
1、-a 添加
-t|u|f service-address -r server-address [-g|i|m](指定lvs的运行模式)[-w weight] [-x upper] [-y lower]
-t|u|f Server-address 已定义好的集群服务
-r server-address 某rs的地址,在nat中可以使用ip:port 实现端口映射
-g:DR
-i:TUN
-m:NAT
-w:weitht
2、-e 修改
3、-d 删除 -t|u|f service-address -r server-address
-t|u|f service-address -r server-address
#ipvsadm –a –t 172.16.100.1:80 –r 192.168.10.8 –m
#ipvsadm –a –t 172.16.100.1:80 –r 192.168.10.9 -m
查看规则:
-L|l
-n:数字格式显示ip及端口号
–stats:进出站的统计信息
–rate :输出速率信息
–timeout:显示tcp、udp、tcpfin的会话超时时间
–daemon
显示进程状态和多播端口
-c 显示当前ipvs的链接状况,多少个客户端链接
–sort 对集群符排序,默认升序
-Z 清空计数器
-C 清空删除所有集群规则
ipvsadm –S > /path/file 保存规则
ipvsadm –R < /path/file 载入规则文件
注意个节点时间得同步,偏差不能超出1s
LVS持久链接
在一定时间内能够将同一个客户端的链接,转发至同一个realserver
持久链接模板|(内存缓存区中),其中维护一个客户端访问表,有cip与realserver的对应关系
Ipvsadm –L –c
Ipvsadm –L -n –persistent-conn 输出持久链接
Ipvsadm –A|E –p timeout #
Timeout 选项来开启持久链接 单位为秒
在基于ssl会话的应用
PPC:同一客户端对同一服务集群的访问始终定向到同一个realserver (lvs负载一个服务)
PCC:同一客户端对所有服务的请求都能够定向到此前选定的同一realserver (lvs 负载了不同的服务)
Ipvsadm –A –t VIP:0 –p
:0将所有的服务都定义成集群服务 即是PCC服务
PNMPP:持久防火墙标记连接,可以将几个不同的服务定义我一个集群而去实现永久链接服务
Lvs real_server 配置VIP、路有需要执行的脚本
#!/bin/bash
VIP=10.100.10.200
host=`/bin/hostname`
case “$1” in
start)
- Start LVS-DR real server on this machine.
/sbin/ifconfig lo down
/sbin/ifconfig lo up
echo “1” >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo “2” >/proc/sys/net/ipv4/conf/lo/arp_announce
echo “1” >/proc/sys/net/ipv4/conf/all/arp_ignore
echo “2” >/proc/sys/net/ipv4/conf/all/arp_announce
#Kernel parameter:设置上面四条命令的原因
Arp_ignore:定义接收到arp请求时的响应级别
0:响应任何接口上,对任何本地ip地址的arp查询请求(任何一个网络接口可以响应,没有配置在其上面的ip信息)
1:仅响应ip地址是来访网络接口本地地址(也就是说这个接口上正好配置了arp请求的ip),的arp查询请求
Arp_announce:定义将自己ip地址向外通告时的通告级别
0:将本地的所有ip地址向外通告
1:试图仅通告与被请求网络接口相匹配的地址
2:仅通告与被请求网络接口匹配的地址
/sbin/ifconfig lo:0 $VIP netmask 255.255.255.255 up
#这条命令是让vip自己的网段内只有自己,这样才不会与其他real_server的VIP发生冲突
/sbin/route add -host $VIP dev lo:0
#用户请求的是VIP地址,但能响应的是RIP,这样响应的源地址就不是用户请求的目标地址,需要加一条路由将VIP封装成源地址,如果目标地址是VIP,则必须通过lo:0接口出去
;;
stop)
Stop LVS-DR real server loopback device(s).
/sbin/ifconfig lo:0 down
echo “0” >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo “0” >/proc/sys/net/ipv4/conf/lo/arp_announce
echo “0” >/proc/sys/net/ipv4/conf/all/arp_ignore
echo “0” >/proc/sys/net/ipv4/conf/all/arp_announce
;;
status)
Status of LVS-DR real server.
islothere=`/sbin/ifconfig lo:0 | grep $VIP`
isrothere=`netstat -rn | grep “lo” | grep $VIP`
if [ ! “$islothere” -o ! “$isrothere” ];then
Either the route or the lo:0 device
not found.
echo “LVS-DR real server is stopped.”
else
echo “LVS-DR real server is running.”
fi
;;
*)
Invalid entry.
echo “$0: Usage: $0 {start|status|stop}”
exit 1
;;
esac
LVS性能优化及故障总结 201612
一、LVS 性能调优的方法最佳实践
1、最小化安装编译系统内核
2、优化持久服务超时时间:
a 、显示超时时间
#ipvsadm -Ln –timeout
#Timeout (tcp tcpfin udp): 900 120 300
b、配置为与自身应用贴近的超时时间
#ipvsadm –set tcp tcpfin udp
没有足够的tcp连接服务器会报:connection reset by peer 问题的原因
01.服务器的并发连接数超过了其承载量,服务器会将其中一些连接关闭
可以使用netstat -an | awk ‘/^tcp/ {++S[$NF]};END {for(a in S)print a,S[a]}’ 命令查看网络连接情况,输出如下:
TIME_WAIT 4715
FIN_WAIT1 1
SYN_SENT 2
ESTABLISHED 151
LISTEN 14
上为tcp状态统计信息,如果 TIME_WAIT 很大,那么我们需要调整tcp的保持时间,这样才能操作正常连接被接收处理,这个值在我们的环境中可以与nginx的keepalive长连接保持一致
02.客户端关掉了浏览器,而服务器还在给客户端发送数据。
03、防火墙的问题
04、lvs 或 nginx tcp保持长连接的时间太长
设置timeout:
ipvsadm –set 1200 5 60
3、网卡中断均衡调度不同的cpu线程上
4、调整内核参数
CONFIG_IP_VS_TAB_BITS
CONFIG_IP_VS_TAB_BITS说明
IPVS connection hash table size,取值范围:[12,20]。该表用于记录每个进来的连接及路由去向的信息。连接的Hash表要容纳几百万个并发连接,任何一个报文到达都需要查找连接Hash表
LVS 有个 connection hash table ,默认的 size 为 4096,可以通过以下命令得到:
ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
hash table 用于记录每个进来的连接及路由去向的信息,连接很多时,4096是肯定不够的,2.6.32 内核之前的内核版本改大需要编译内核,下载到root
wget http://vault.centos.org/6.3/updates/Source/SPackages/kernel-2.6.32-279.19.1.el6.src.rpm
rpm -ivh kernel-2.6.32-279.19.1.el6.src.rpm
cd /root/rpmbuild/SOURCES
vim config-generic 把 第一行的 # 改成 # x86_64,把 CONFIG_IP_VS_TAB_BITS=12 改成 CONFIG_IP_VS_TAB_BITS=20
cd /root/rpmbuild/SPECS
vim kernel.spec 把 # % define buildid .local 修改为 %define buildid .ipvs_20bit
rpmbuild -bb –target=$(uname -m) –with firmware kernel.spec (-bb是编译成rpm包,-ba是编译成rpm和src.rpm包)
注意内核编译需要很长时间耐心等待
在 /root/rpmbuild/RPMS/x86_64/ 看到编译出来的包:
kernel-2.6.32-279.19.1.el6.ipvs_20bit.x86_64.rpm
kernel-devel-2.6.32-279.19.1.el6.ipvs_20bit.x86_64.rpm
kernel-firmware-2.6.32-279.19.1.el6.ipvs_20bit.x86_64.rpm
在机器上只要安装三个包即可,安装之后重启机器,然后安装lvs 既可以看到 hash size 变成了 1048576,2的20次方
建议将hash table的值设置为不低于并发连接数。例如,并发连接数为200,Persistent时间为200S,那么hash桶的个数应设置为尽可能接近200×200=40000,2的15次方为32768就可以了。当ip_vs_conn_tab_bits=20 时,哈希表的的大小(条目)为 pow(2,20),即 1048576,对于64位系统,IPVS占用大概16M内存,可以通过demsg看到:IPVS: Connection hash table configured (size=1048576, memory=16384Kbytes)。对于现在的服务器来说,这样的内存占用不是问题。所以直接设置为20即可。
关于最大”连接数限制”:这里的hash桶的个数,并不是LVS最大连接数限制。LVS使用哈希链表解决”哈希冲突”,当连接数大于这个值时,必然会出现哈稀冲突,会(稍微)降低性能,但是并不对在功能上对LVS造成影响。
内核版本高于2.6.32调整 ip_vs_conn_tab_bits的方法:
在发行版里,IPVS通常是以模块的形式编译的。
确认能否调整使用命令 modinfo -p ip_vs(查看 ip_vs 模块的参数),看有没有 conn_tab_bits 参数可用。假如可以用,那么说时可以调整,调整方法是加载时通过设置 conn_tab_bits参数:
在/etc/modprobe.d/目录下添加文件ip_vs.conf,内容为:
options ip_vs conn_tab_bits=20
查看
ipvsadm -l
如果显示IP Virtual Server version 1.2.1 (size=4096),则前面加的参数没有生效
modprobe -r ip_vs
modprobe ip_vs
重新查看
IP Virtual Server version 1.2.1 (size=1048576)
5、lvs 关闭分片整合功能,关闭网卡 GRO 和 LRO
什么是GRO (Generic receive offload):
大家都知道网络上MTU是最大传输单元,一般是1500字节,如果一个包超过MTU,就会被分片,但是如果一个路由器的带宽处理能力是10Gbps,如果满负载跑,数据包会被分成相当多个片,性能肯定有影响。所以就有了GRO,它在网卡上间接提高了MTU,它把满足一定条件(比较严格)的包,将分片的包组装合并了,才一次性交给上面的协议栈。但是GRO 和 LVS 协作得并不好,具体表现就是,POST 数据到 LVS 很慢(可以抓包),所以要关闭。
包太大会丢包(待测)。
通过 ethtool -k em1 ,来查看是否有 generic-receive-offload: on , on 表示开启。
LRO(Large Receive Offload) 和 GRO 是相似的,只不过GRO 克服了LRO的一些缺点,更通用,LRO基本上不用了。
关闭方法(默认lro 是关闭了的):
ethtool -K 网卡(如em1) gro off
ethtool -K 网卡(如em1) lro off
二、故障总结
01、lvs频繁踢掉后台rs的故障处理
症结:mount磁盘时没有加上noatime参数,大量磁盘io中的write操作,导致检查url超时
lvs老是踢掉后台rs,系统日志经常出现这样的情况:
May 1 10:54:41 hz84-234 Keepalived_healthcheckers: Timeout HTTP read server [10.1.1.1:80].
May 1 10:54:41 hz84-234 Keepalived_healthcheckers: Removing service [10.1.1.1:80] from VS [10.1.1.1:80]
May 1 10:54:41 hz84-234 Keepalived_healthcheckers: Remote SMTP server [127.0.0.1:25] connected.
May 1 10:54:41 hz84-234 Keepalived_healthcheckers: SMTP alert successfully sent.
May 1 10:54:44 hz84-234 Keepalived_healthcheckers: HTTP status code success to [10.1.1.1:80] url(1).
May 1 10:54:47 hz84-234 Keepalived_healthcheckers: Remote Web server [10.1.1.1:80] succeed on service.
May 1 10:54:47 hz84-234 Keepalived_healthcheckers: Adding service [10.1.1.1:80] to VS [10.1.1.1:80]
现象是:踢出去,立即加进来
分析原因:
首先根据日志,表面上看是超时,于是tcpdump抓了lvs过来的检测调用,分析了一会没发现什么异常,当然也没发现是谁主动断开了连接,看rs的apache访问日志里,lvs过来的健康检查,的确有很多超过5s的响应,不理解原因,把keepalived超时参数由5s增加为25s,故障还是出现, iostat,然后抓 iostat 30 磁盘阻塞
mount了一下,发现了问题,原来 cache 文件所在的 /home 分区挂载的时候没有noatime参数,于是果断加上,reboot机器,问题得以解决,io下来了,lvs也不踢后台了。
iostat 30 ,周一没有加notime,18:40的情况:
avg-cpu: %user %nice %system %iowait %steal %idle
1.94 0.00 0.93 1.72 0.00 95.42
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 52.83 9.07 948.27 272 28448
sda1 0.50 0.00 12.53 0 376
sda2 0.00 0.00 0.00 0 0
sda3 0.30 0.00 14.13 0 424
sda4 0.00 0.00 0.00 0 0
sda5 0.47 0.00 5.87 0 176
sda6 0.30 0.00 6.13 0 184
sda7 51.27 9.07 909.60 272 27288
sdb 0.00 0.00 0.00 0 0
sdb1 0.00 0.00 0.00 0 0
优化过之后的效果(磁盘写操作下降到了原来的 1/10):
avg-cpu: %user %nice %system %iowait %steal %idle
1.09 0.00 0.57 0.59 0.00 97.74
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 4.97 14.66 101.30 440 3040
sda1 0.27 0.00 3.20 0 96
sda2 0.00 0.00 0.00 0 0
sda3 0.03 0.00 0.27 0 8
sda4 0.00 0.00 0.00 0 0
sda5 0.23 0.00 2.67 0 80
sda6 0.13 0.00 2.93 0 88
sda7 4.30 14.66 92.24 440 2768
sdb 0.00 0.00 0.00 0 0
sdb1 0.00 0.00 0.00 0 0
02、lvs可能没有刷新mac地址列表,导致无法转发,keepalived不存在这个问题
刷新命令:
/sbin/arping -I eth0 -c 3 -s ${vip} ${gateway_ip} > /dev/null 2>&1
这个命令不一定非要在VS上执行,只要在同一VLAN即可:/sbin/arping -f -q -c 5 -w 5 -I eth0 -s $WEB_VIP -U $GW
03、lvs不能负载均衡多部分连接只到某一台机器上
这和LVS脚本里指定-p(对于keepalived的presistent )参数有关,如果指定了一个client在一定的时间内,将会被调度到同一台RS上。所以你在从来源来做压力测试的时候大部分连接会调度到同一台机器上,这样就出现了负载不均衡的状况。
04、大量请求并发时lvs会出现转发停顿
转发量大了lvs的极限,hash size 值小,tcp 连接无法即时释放
05、在LVS方案中,虚拟ip地址与普通网络接口不同,这点需要特别注意
虚拟ip地址的广播地址是它本身,子网掩码是255.255.255.255。 为什么要这样呢?因为有若干机器要使用同一个ip地址,用本身做广播地址和把子网掩码设成4个255就不会造成ip地址冲突了,否则lvs将不能正常转发访问请求。
06关于keepalived Real_server 过多导致进程崩溃
使用的是keepalived做健康检查
因为目前使用VIP的数量有200左右. 每个VIP下面realserver约在5-10个左右
每个keepalived所管理的realserver数量大概在1100个左右,keepalived进程就会挂掉,然后进入无限循环
现在只有keepalvied start 或是 keepalived reload 都会在出现大量这样的日志
Jul 14 19:47:07 b02 Keepalived_healthcheckers[14203]: Cannot send get request to [10.15.200.200]:80.
Jul 14 19:47:07 b02 Keepalived_healthcheckers[14203]: Removing service [10.100.200.200]:80 from VS [10.15.177.177]:80
Jul 14 19:47:07 b02 Keepalived_healthcheckers[14203]: SMTP connection ERROR to [127.0.0.1]:25.
Jul 14 19:47:07 b02 Keepalived[13055]: Healthcheck child process(14203) died: Respawning
Jul 14 19:47:07 b02 Keepalived[13055]: Starting Healthcheck child process, pid=14525
Jul 14 19:47:07 b02 Keepalived_healthcheckers[14525]: Interface queue is empty
Jul 14 19:47:07 b02 Keepalived_healthcheckers[14525]: No such interface, eth1
Jul 14 19:47:07 b02 Keepalived_healthcheckers[14525]: No such interface, usb0
Jul 14 19:47:07 b02 Keepalived_healthcheckers[14525]: No such interface, bond0
系统参数__FD_SETSIZE限制 ,因为keepalived使用select模式,默认select限制 1024个socket连接
keepalived 是集群管理中保证集群高可用的一个服务软件,其功能用来防止单点故障,可以说与lvs结合最紧密的一个高可用插件,具体结合 lvs 就是防止lvs发生单点故障而导致整个网站不可用,针对web服务提供url检查功能
keepalived 是利用vrrp虚拟路由冗余协议转移VIP来实现高可用,vrrp设计之初是为了防止路由器的单点故障
keepalived 通过配置文件实对ip_vs的管理,只是替代了ipvsadm对lvs规则生成,管理、监控、查看还需ipvsadm
keepalived 针对web服务提供url检查功能,可自定义一些监控脚本
注意keepalived 启动不检查语法,即使没有配置文件也能启动,所以重启或重载配置文件后一定要检查服务是否正常
keepalive的网络响应模式是select所以最大的响应链接为1024,超过1024会报障
下面keepalived详解出场,网上下载的比较全大家研究
keepalived工作原理和配置说明
keepalived是什么
keepalived是集群管理中保证集群高可用的一个服务软件,其功能类似于heartbeat,用来防止单点故障。
keepalived工作原理
keepalived是以VRRP协议为实现基础的,VRRP全称Virtual Router Redundancy Protocol,即虚拟路由冗余协议。
虚拟路由冗余协议,可以认为是实现路由器高可用的协议,即将N台提供相同功能的路由器组成一个路由器组,这个组里面有一个master和多个backup,master上面有一个对外提供服务的vip(该路由器所在局域网内其他机器的默认路由为该vip),master会发组播,当backup收不到vrrp包时就认为master宕掉了,这时就需要根据VRRP的优先级来选举一个backup当master。这样的话就可以保证路由器的高可用了。
keepalived主要有三个模块,分别是core、check和vrrp。core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。check负责健康检查,包括常见的各种检查方式。vrrp模块是来实现VRRP协议的。
keepalived的配置文件
keepalived只有一个配置文件keepalived.conf,里面主要包括以下几个配置区域,分别是global_defs、static_ipaddress、static_routes、vrrp_script、vrrp_instance和virtual_server。
global_defs区域
主要是配置故障发生时的通知对象以及机器标识
global_defs {
notification_email {
a@abc.com
b@abc.com
…
}
notification_email_from alert@abc.com
smtp_server smtp.abc.com
smtp_connect_timeout 30
enable_traps
router_id host163
}
- notification_email 故障发生时给谁发邮件通知。
- notification_email_from 通知邮件从哪个地址发出。
- smpt_server 通知邮件的smtp地址。
- smtp_connect_timeout 连接smtp服务器的超时时间。
- enable_traps 开启SNMP陷阱(Simple Network Management Protocol)。
- router_id 标识本节点的字条串,通常为hostname,但不一定非得是hostname。故障发生时,邮件通知会用到。
static_ipaddress和static_routes区域
static_ipaddress和static_routes区域配置的是是本节点的IP和路由信息。如果你的机器上已经配置了IP和路由,那么这两个区域可以不用配置。其实,一般情况下你的机器都会有IP地址和路由信息的,因此没必要再在这两个区域配置。
static_ipaddress {
10.210.214.163/24 brd 10.210.214.255 dev eth0
…
}
static_routes {
10.0.0.0/8 via 10.210.214.1 dev eth0
…
}
以上分别表示启动/关闭keepalived时在本机执行的如下命令:
- /sbin/ip addr add 10.210.214.163/24 brd 10.210.214.255 dev eth0
- /sbin/ip route add 10.0.0.0/8 via 10.210.214.1 dev eth0
- /sbin/ip addr del 10.210.214.163/24 brd 10.210.214.255 dev eth0
- /sbin/ip route del 10.0.0.0/8 via 10.210.214.1 dev eth0
注意: 请忽略这两个区域,因为我坚信你的机器肯定已经配置了IP和路由。vrrp_script区域
用来做健康检查的,当时检查失败时会将vrrp_instance的priority减少相应的值。
vrrp_script chk_http_port {
script “</dev/tcp/127.0.0.1/80”
interval 1
weight -10
}
以上意思是如果script中的指令执行失败,那么相应的vrrp_instance的优先级会减少10个点。vrrp_instance和vrrp_sync_group区域
vrrp_instance用来定义对外提供服务的VIP区域及其相关属性。
vrrp_rsync_group用来定义vrrp_intance组,使得这个组内成员动作一致。举个例子来说明一下其功能:
两个vrrp_instance同属于一个vrrp_rsync_group,那么其中一个vrrp_instance发生故障切换时,另一个vrrp_instance也会跟着切换(即使这个instance没有发生故障)。
vrrp_sync_group VG_1 {
group {
inside_network # name of vrrp_instance (below)
outside_network # One for each moveable IP.
…
}
notify_master /path/to_master.sh
notify_backup /path/to_backup.sh
notify_fault “/path/fault.sh VG_1”
notify /path/notify.sh
smtp_alert
}
vrrp_instance VI_1 {
state MASTER
interface eth0
use_vmac <VMAC_INTERFACE>
dont_track_primary
track_interface {
eth0
eth1
}
mcast_src_ip <IPADDR>
lvs_sync_daemon_interface eth1
garp_master_delay 10
virtual_router_id 1
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 12345678
}
virtual_ipaddress {
10.210.214.253/24 brd 10.210.214.255 dev eth0
192.168.1.11/24 brd 192.168.1.255 dev eth1
}
virtual_routes {
172.16.0.0/12 via 10.210.214.1
192.168.1.0/24 via 192.168.1.1 dev eth1
default via 202.102.152.1
}
track_script {
chk_http_port
}
nopreempt
preempt_delay 300
debug
notify_master <STRING>|<QUOTED-STRING>
notify_backup <STRING>|<QUOTED-STRING>
notify_fault <STRING>|<QUOTED-STRING>
notify <STRING>|<QUOTED-STRING>
smtp_alert
}
- notify_master/backup/fault 分别表示切换为主/备/出错时所执行的脚本。
- notify 表示任何一状态切换时都会调用该脚本,并且该脚本在以上三个脚本执行完成之后进行调用,keepalived会自动传递三个参数($1 = “GROUP”|”INSTANCE”,$2 = name of group or instance,$3 = target state of transition(MASTER/BACKUP/FAULT))。
- smtp_alert 表示是否开启邮件通知(用全局区域的邮件设置来发通知)。
- state 可以是MASTER或BACKUP,不过当其他节点keepalived启动时会将priority比较大的节点选举为MASTER,因此该项其实没有实质用途。
- interface 节点固有IP(非VIP)的网卡,用来发VRRP包。
- use_vmac 是否使用VRRP的虚拟MAC地址。
- dont_track_primary 忽略VRRP网卡错误。(默认未设置)
- track_interface 监控以下网卡,如果任何一个不通就会切换到FALT状态。(可选项)
- mcast_src_ip 修改vrrp组播包的源地址,默认源地址为master的IP。(由于是组播,因此即使修改了源地址,该master还是能收到回应的)
- lvs_sync_daemon_interface 绑定lvs syncd的网卡。
- garp_master_delay 当切为主状态后多久更新ARP缓存,默认5秒。
- virtual_router_id 取值在0-255之间,用来区分多个instance的VRRP组播。
注意: 同一网段中virtual_router_id的值不能重复,否则会出错,相关错误信息如下。
Keepalived_vrrp[27120]: ip address associated with VRID not present in received packet :
one or more VIP associated with VRID mismatch actual MASTER advert
bogus VRRP packet received on eth1 !!!
receive an invalid ip number count associated with VRID!
VRRP_Instance(xxx) ignoring received advertisment…
可以用这条命令来查看该网络中所存在的vrid:tcpdump -nn -i any net 224.0.0.0/8
- priority 用来选举master的,要成为master,那么这个选项的值最好高于其他机器50个点,该项取值范围是1-255(在此范围之外会被识别成默认值100)。
- advert_int 发VRRP包的时间间隔,即多久进行一次master选举(可以认为是健康查检时间间隔)。
- authentication 认证区域,认证类型有PASS和HA(IPSEC),推荐使用PASS(密码只识别前8位)。
- virtual_ipaddress vip,不解释了。
- virtual_routes 虚拟路由,当IP漂过来之后需要添加的路由信息。
- virtual_ipaddress_excluded 发送的VRRP包里不包含的IP地址,为减少回应VRRP包的个数。在网卡上绑定的IP地址比较多的时候用。
- nopreempt 允许一个priority比较低的节点作为master,即使有priority更高的节点启动。
首先nopreemt必须在state为BACKUP的节点上才生效(因为是BACKUP节点决定是否来成为MASTER的),其次要实现类似于关闭auto failback的功能需要将所有节点的state都设置为BACKUP,或者将master节点的priority设置的比BACKUP低。我个人推荐使用将所有节点的state都设置成BACKUP并且都加上nopreempt选项,这样就完成了关于autofailback功能,当想手动将某节点切换为MASTER时只需去掉该节点的nopreempt选项并且将priority改的比其他节点大,然后重新加载配置文件即可(等MASTER切过来之后再将配置文件改回去再reload一下)。
当使用track_script时可以不用加nopreempt,只需要加上preempt_delay 5,这里的间隔时间要大于vrrp_script中定义的时长。
- preempt_delay master启动多久之后进行接管资源(VIP/Route信息等),并提是没有nopreempt选项。
virtual_server_group和virtual_server区域
virtual_server_group一般在超大型的LVS中用到,一般LVS用不过这东西,因此不多说。
virtual_server IP Port {
delay_loop <INT>
lb_algo rr|wrr|lc|wlc|lblc|sh|dh
lb_kind NAT|DR|TUN
persistence_timeout <INT>
persistence_granularity <NETMASK>
protocol TCP
ha_suspend
virtualhost <STRING>
alpha
omega
quorum <INT>
hysteresis <INT>
quorum_up <STRING>|<QUOTED-STRING>
quorum_down <STRING>|<QUOTED-STRING>
sorry_server <IPADDR> <PORT>
real_server <IPADDR> <PORT> {
weight <INT>
inhibit_on_failure
notify_up <STRING>|<QUOTED-STRING>
notify_down <STRING>|<QUOTED-STRING>
# HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK
HTTP_GET|SSL_GET {
url {
path <STRING>
# Digest computed with genhash
digest <STRING>
status_code <INT>
}
connect_port <PORT>
connect_timeout <INT>
nb_get_retry <INT>
delay_before_retry <INT>
}
}
}
- delay_loop 延迟轮询时间(单位秒)。
- lb_algo 后端调试算法(load balancing algorithm)。
- lb_kind LVS调度类型NAT/DR/TUN。
- virtualhost 用来给HTTP_GET和SSL_GET配置请求header的。
- sorry_server 当所有real server宕掉时,sorry server顶替。
- real_server 真正提供服务的服务器。
- weight 权重。
- notify_up/down 当real server宕掉或启动时执行的脚本。
- 健康检查的方式,N多种方式。
- path 请求real serserver上的路径。
- digest/status_code 分别表示用genhash算出的结果和http状态码。
- connect_port 健康检查,如果端口通则认为服务器正常。
- connect_timeout,nb_get_retry,delay_before_retry分别表示超时时长、重试次数,下次重试的时间延迟。
keepalived主从切换
主从切换需要人工干预,需要将backup配置文件的priority选项的值调整的比master高50个点,然后reload配置文件就可以切换了。当然你也可以将master的keepalived停止,这样也可以进行主从切换。
keepalived仅做HA时的配置
请看该文档同级目录下的配置文件示例。
说明:10.210.214.113 为keepalived的备机,其配置文件为113.keepalived.conf10.210.214.163 为keepalived的主机,其配置文件为163.keepalived.conf10.210.214.253 为Virtual IP,即提供服务的内网IP地址,在网卡eth0上面192.168.1.11 为模拟的提供服务的公网IP地址,在网卡eth1上面
用tcpdump命令来捕获的结果如下:
17:20:07.919419 IP 10.210.214.163 > 224.0.0.18: VRRPv2, Advertisement, vrid 1, prio 200, authtype simple, intvl 1s, length 20
LVS+Keepalived配置
注Keepalived与LVS结合使用时一般还会用到一个工具ipvsadm,用来查看相关VS相关状态,关于ipvsadm的用法可以参考man手册。
10.67.15.95为keepalived master,VIP为10.67.15.94,配置文件为95-lvs-keepalived.conf10.67.15.96为keepalived master,VIP为10.67.15.94,配置文件为96-lvs-keepalived.conf10.67.15.195为real server
注意:
当使用LVS+DR+Keepalived配置时,需要在real server上添加一条iptables规则(其中dport根据情况添加或缺省):
- iptables -t nat -A PREROUTING -p tcp -d 10.67.15.94 –dport 80 -j REDIRECT
当使用LVS+NAT+Keepalived配置时,需要将real server的默认路由配置成Director的VIP10.67.15.94,必须确保client的请求是通过10.67.15.94到达real server的。安装keepalived
从keepalived官网下载合适的版本,解压并执行如下命令完成安装。
- cd keepalived-xxx
- ./configure –bindir=/usr/bin –sbindir=/usr/sbin –sysconfdir=/etc –mandir=/usr/share
-
make && make install
说明
我们用到的HA场景如下: 两台主机host113和host163,内网IP在eth1网卡上,分别是10.210.214.113和10.210.214.163,VIP为公网IP在eth0上,IP地址是202.102.152.253,网关为202.102.152.1。当VIP在host113上提供服务时,host113上的默认路由为202.102.152.1,提供服务的端口为202.102.152.253:443。host113发生故障需要将VIP及服务切回到host163上的时候,需要以下几步,第一将VIP接管过来,第二添加默认路由202.102.152.1,第三启动在端口202.102.152.253:443上的服务。
如此一来,keepalived需要另外的脚本来完成添加默认路由和启动服务工作,这点和heartbeat中的resources是相同的。目前我进行了测试,发现keepalived速度要比heartbeat快,也就是说效率比heartbeat高。并且,最重要的一点,keepalived支持多个backup。
不要问我为何有以上需求。要为两个不同的域名提供https服务,由于SSL证书问题,必须有两个公网IP地址分别绑定443端口。
当然,通过SNI也可以实现一个公网IP绑定443端口来为多个域名提供https服务,但是这需要浏览器支持(M$的IE浏览器不支持)。(nginx/apache)
吐槽
keepalived 启动不检查配置文件语法,即使没有配置文件也会启动,生成环境中启动keepalived后一定要ipvsadm –ln来查看服务连接是否正常
keepalived 是通过vrrp协议来实现高可用,主备切好必需要通过手动关闭主的keepalived进程或调高backup的优先级才能实现,注意
原创文章,作者:赛福,如若转载,请注明出处:https://www.safecdn.cn/377.html
本站不销售、不代购、不提供任何支持,仅分享网络信息,请自行辨别,请遵纪守法、文明上网。 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
Google镜像站
Google镜像: https://vvpn.499994.xyz/googlebak.html (Google网页和学术和内含各种FQ) http://ac.scmor.com/…
-
WinMTR工具详解
WinMTR工具: 该工具包括PING和tracert两种测试。具体使用方法及对照的参数如下: Hostname:到目的服务器要经过的每个主机IP或名称Nr:经过节点的数量;Los…
-
8.什么是OpenFlow?
OpenFlow(OF)被认为是第一个软件定义网络(SDN)标准之一。它最初在SDN环境中定义了通信协议,使SDN 控制器能够与物理和虚拟(基于管理程序)的交换机和路由器等网络设…
-
自定义Access-Control-Allow-Origin策略以解决字体文件跨域权限问题
什么是Access-Control-Allow-Origin Access-Control-Allow-Origin是HTML5中定义的一种服务器端返回Response heade…
-
运维常用linux命令
==================================1文件管理 2软件管理 3系统管理4服务管理 5网络管理 6磁盘管理7用户管理 8脚本相关 9服务配置=====…
-
Nginx-HTTP状态码:499
google定义:499 / ClientClosed Request An Nginx HTTP server extension. This codeis introduced…
-
17.什么是SDN业务流程?
软件定义网络(SDN) 编排(或SDN编制或SDN策略编排)能够对网络中的自动行为进行编程,以协调所需的网络硬件和软件元素以支持应用程序和服务。 SDN编排可以从客户服务订单开始…
-
7.什么是OpenDaylight项目(ODL)?
为了推动软件定义网络(SDN)的采用并为强大的网络功能虚拟化(NFV)奠定基础,于2013年4月宣布成立由Linux基金会主办的开源SDN项目OpenDaylight项目(ODL …
-
25.什么是思科应用策略基础设施控制器(APIC)?第3部分
什么是思科应用策略基础架构控制器 是SDxCentral系列的第一部分,用于解释 思科ACI(应用中心基础架构) 框架。查看 详细介绍思科应用策略基础架构控制器或思科API…
-
nginx禁止IP或目录访问
1.nginx禁止访问所有.开头的隐藏文件设置 location ~* /.* { deny all; } 2.nginx禁止访问目录 例如:禁止访问path目录 location…